Stable diffusion原理解析
笔记由B站大佬ZHO的科普视频 学习整理而成。
LLM进化树
%203.jpg)
图像生成模型
- GAN 生成对抗模型, 生成模型VS判别模型
- VAE
- Flow
- Diffusion Model
#todo/图像生成论文: 《what are diffusion models》论文详细阅读,介绍了更多的图像生成模型
Diffusion models
两个过程
- 正向扩散:通过添加噪声来扰动数据分布
- 反向传播:将噪声从数据中去除,生成图像
#todo/图像生成论文: 《Diffusion Models: A Comprehensive Survey of Methods and Applications》
扩散模型的三大基础
- DDPM
- SGM
- Scope SDE
扩散模型的分类
- 高效采样
- 最大似然增强
- 结构化数据
扩散模型的六大应用领域
- 计算机视觉
- 自然语言生成
- 时态数据建模
- 多模态学习
- 鲁棒学习
- 跨学科学习
#todo/视频课程: Google deenlearningAI, 《How Diffusion Models Work》
Stable Diffusion 发展线梳理

主线
基础
- Deep Unsupervised Learning using Nonequilibrium Thermodynamics:
- DDPM:15年提出的扩散概率模型,经过ddpm的改进之后,逐渐进入人们的视野。ddpm将“去噪”扩散概率模型应用到图像中,并且通过固定前向过程的方差、选择合适的反向过程参数化,以及使用高斯分布来表示条件概率,设计出了简单高效的扩散模型
- SDM
- Scope SDE
- DDPM、SDM、Scope SDE三大基础论文,奠定了扩散概率模型在图像生成领域的基础
- 基于分数的生成模型SGM和扩散概率模型DDPM都可以视为由分数函数确定的随机微分方式Score SDE的离散化
- 分数生成模型和扩散概率模型被连接到一个统一的框架中
高效采样
- 2020年10月,DDIM被提出,弃用马尔科夫链,采样速度提升50倍,反向降噪转变为确定性过程,首次拥有一致性
- 2021年2月,OpenAI提出improved-diffusion,生成速度和质量有了比较大的飞跃。
引导扩散
- 2021年5月,OpenAI发布《diffusionmodel beats GANs on image synthesis》,提出guided-diffusion,通过增加分类器作为引导,用多样性换取写实性。但是引导函数与扩散模型是分开训练的,无法联合训练。
- 2021年底,DDPM作者提出了无需额外的分类器的扩散引导方法,classifier-free diffusion guidance, CFG(即后来SD中的CFG参数)。训练模型的成本大大增加
- 2021年12月,OpenAI的新论文GLIDE,对比了用CLIP模型做引导,和CFG无分类器做引导的方法,后者更受青睐,虽然训练成本更高。 OpenAi训练出基于无分类器引导的全新模型GLIDE,拥有35亿参数量的超大规模文生图扩散模型,也可用于图像修复,实现了基于文本驱动的图像编辑功能
Clip + Diffusion
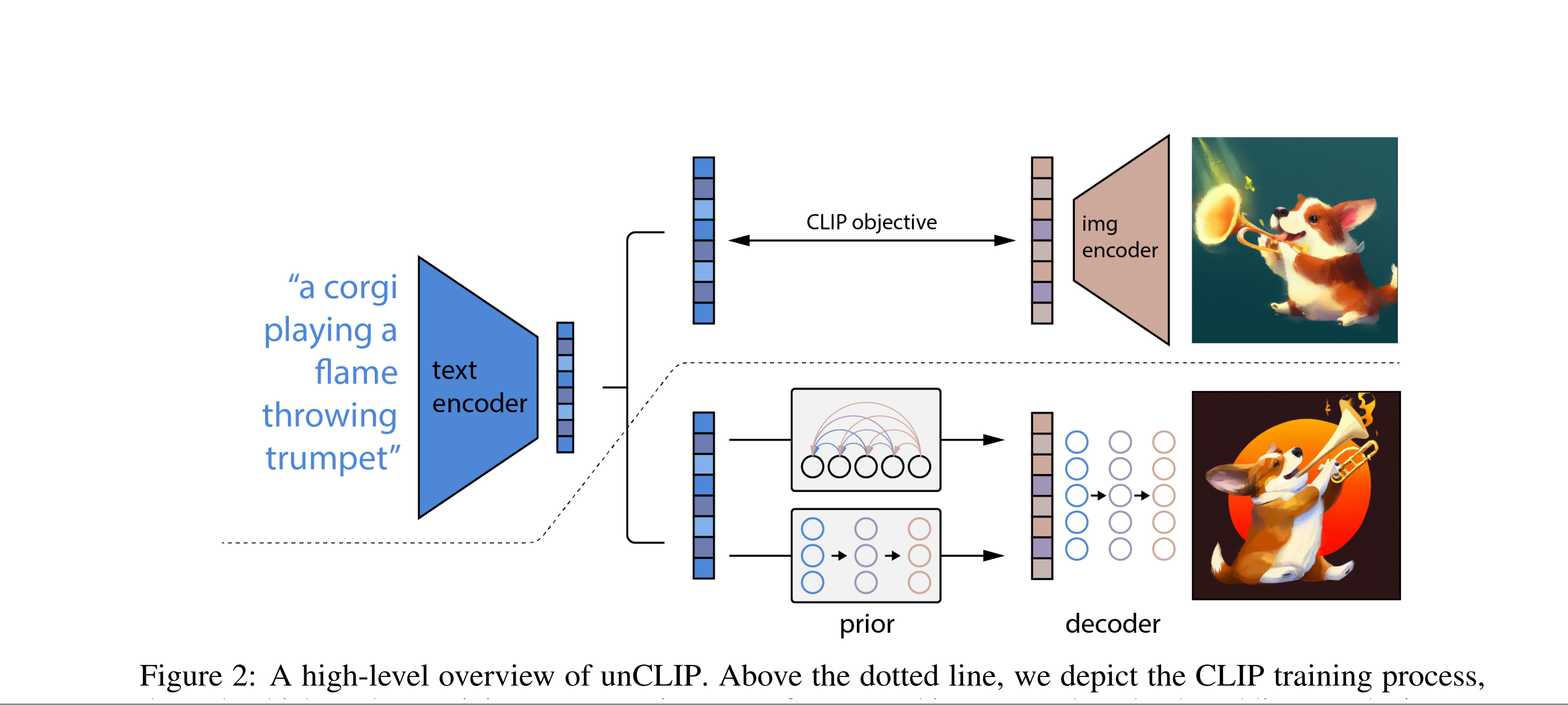
- 2022年4月,DALL·E 2诞生,基本思想是CLIP和GLIDE的结合,模型名取自萨尔瓦多达利(Salvador Dali)和Wall·E. unClip,反转Clip编码器
- 第一阶段的先验模型接受编码后的文本嵌入作为输入,经过prior采样之后生成一个CLIP图像嵌入
- 第二阶段的解码器,以上一阶段的图像嵌入作为输入来生成最终图像
- 实现了输入既可以是文字,也可以是图像。
- 此时扩散模型可以从现有图像中获取概念,并基于此概念而生存保留原本语义和风格的图像变体
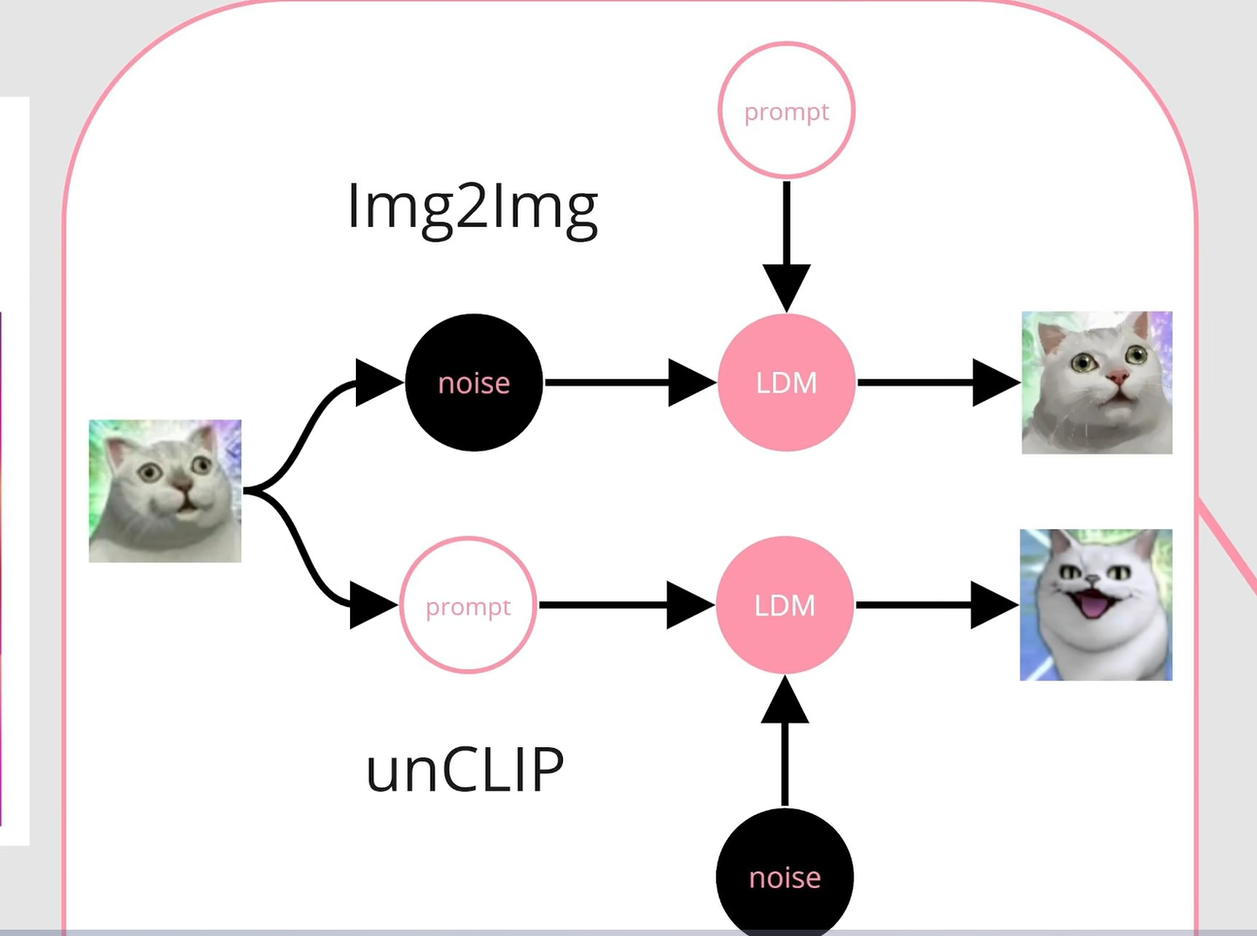
- 图生图与unCLIP的区别:
- 图生图(图像作为噪声进入模型):构图等方面与原图相似,仅在细节方面产生变化,适合图像做微调、修复等场景
- unCLIP(图像作为提示词进入模型):输入的图被编码后变为提示词输入到模型中,对于模型来说,是提取概念后重新生成的过程,构图与细节与原图不同




- 同年5月,Google推出语言模型T5和DM结合的新模型Imagen
潜空间扩散模型LDM
- 21年12月,LDM V1
- 22年4月, LDM V2,14.5亿参数量的LDM模型
- 将原本在像素层面运行的扩散模型降低维度到潜空间进行,降低训练和运算成本
- 增加了交叉注意力层,支持多种条件输入
SD
- 2022年8月,SD公开版正式发布,CompVis牵头,stability AI、runaway等共同合作,以LDM架构为基础,在LAION-5B的子集上完成训练,可以生成512 * 512分辨率的图像。使用CLIP VIT-L作为文本编码器。可以在10GB级别显卡上运行
- 2022年11月底,stability AI宣布推出SD 2.0
- 12月初推出SD 2.1,图像模型进入以SD为核心的LDM时代
微调
- 22年8月,英伟达提出的embedding模型,An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
- 同月,谷歌发布论文DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation,进入个性化微调时代
- 2022年12月, LoRA for DM用于扩散模型的微调
控制
- GLIGEN,擅长指定位置生成
- 文本+框,图像+框,图像风格+文本+框,文本实体+关键点


- 文本+框,图像+框,图像风格+文本+框,文本实体+关键点
- Control Net
- T2I-Adapter:对生成速度有要求或者算力有限,建议使用T2I
SDXL新架构
- 23年4月份,stability ai推出SDXL beta, 6月推出SDXL 0.9 SDXL,新架构模块化,新增精调模型
- 7月底正式发布SDXL 1.0, 可以生成1024 * 1024高清图
后续发展
- stability ai推出谷歌Imagen的复现模型IF,可以解决文字生成、空间位置关系理解等问题
- 2023年5月 stability ai 推出文生动画模型stable animation SDK
image prompt (类unclip)
- Revision:Revision is a novel approach of using images to prompt SDXL.
- 腾讯Ip-adapter
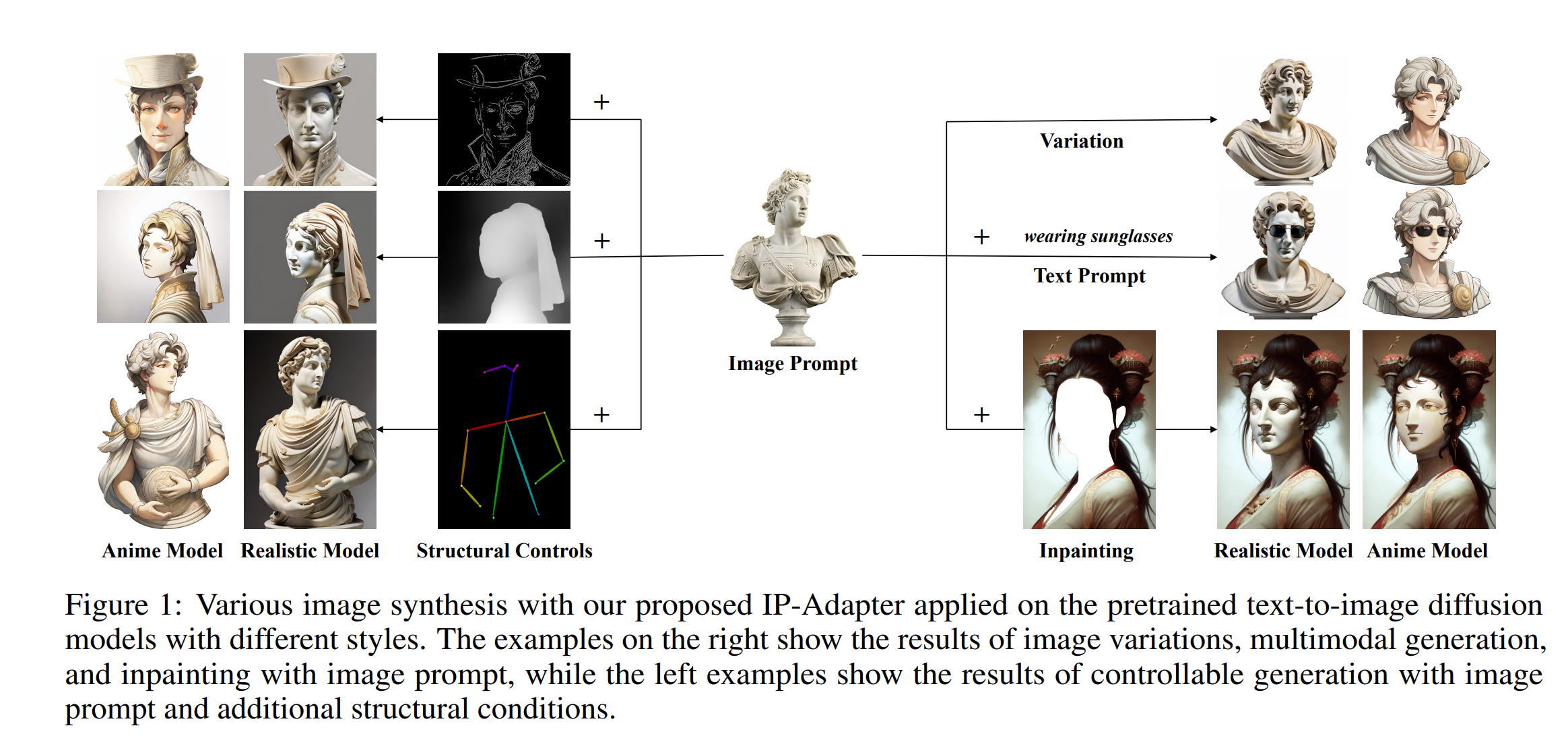
辅线
CLIP
- 2021年2月,OpenAI提出拥有超强零样本迁移能力的CLIP模型,图像与文本之间的向量转化
微调
- 2016年9月,语言模型微调的hypernetworks
- 2021年6月,微软提出LoRA用于微调大语言模型
LAION-400M数据集
- 2022年3月,全球最大的公开数据集LAION-5B发布
SD UI的发展
- SD V1发布的同月,最著名的SD web UI开源发布
- 23年1月,comfyUI开源发布
- foocus UI上线,专注提示词和图像,没有复杂参数调整,安装简单,显卡要求更低4GB